What Stephen King has taught me about Google’s Knowledge Graph
Imagine that you’re in your local bookshop and you want to buy the latest Stephen King book, what steps would you unconsciously follow to do this? I can’t speak for everyone, but here is what I would do:
-
Look at the books, stay away from board games and gifts
-
Locate the Horror section
-
Browse the authors alphabetically, look for “K”
-
Check the publish dates for the books to see which one is most recent
Alternatively, you could ask a member of staff who will look it up on their computer. The chances are, they will look for similar information.
So why is this relevant to SEO? Well, let’s have another look at that process and define what we’re looking for; we’re looking for a book, genre, author and publish date. These are all pieces of information that Google also store in relation to this book. We call them entities!
Let’s talk about schema baby
If you work in SEO, there’s a good chance that you’ve heard of schema, or structured data. However, not everyone understands exactly what it is. So let’s look at the above example and show what it would look like in JSON format. At the time of writing, the following are the details of the book which I’ve described.:
"@type": "https://schema.org/Book",
"name": "The Life of Chuck",
"datePublished": "2025-06-10",
"genre": "horror",
"author": {
"@type": "https://schema.org/Person",
"name": "Stephen King"
}
This is a (very) simplified version of how Google will store information about this book. So why is that important? Well the short answer is money and speed.
In the olden days, search engines used to look at the keywords in your search query then search every single page in its index for references to that keyword. This is the equivalent to going into your local bookshop and looking at every single book until you’ve found the one you’re looking for. That would be exhausting! So in 2012, Google announced the knowledge graph, which is a kind of database which organises entities and their relationships to each other.
In 2013 Google also released hummingbird which uses natural language processing (NLP) to understand search queries and serve the best answers. So let’s have a look at the bookshop task from earlier and turn it into a Google search:

We can break the query down into 3 elements:
-
Publish date - “latest”
-
Author - “stephen king”
-
Entity type - “book”
Google then uses NLP to understand what you’re trying to find from that query and return the best results. As you can see in the screenshot, Google has answered the question within the autocomplete. This is not down to LLMs or AI Overviews, but a simple understanding of the search query and the results.
Let’s go back to your bookshop task from the start of the article, the steps you have taken to find the book involve navigating to the books, then the horror section then looking for the correct author. This enables you to avoid looking at 95% of the store and focus only on the section of books you’re interested in - thus avoiding the painful task of looking through every single book in the shop. Similarly, Google knows that you’re looking for a book from a specific author so it can ignore 99% of its index. This saves you time and it saves them money.
You gotta have confidence
Imagine you want to find a Stephen King book published in the 1970s about a haunted Colorado hotel. What would you search for in Google?
You said “The Shining” didn’t you? It’s a good answer, but its wrong. What you would actually get is the 1980 Stanley Kubrick movie starring Jack Nicholson. Close, but not the same.

Since a entity name can be applied to multiple entities, Google has to make a best guess as to which one you’re referring to. For this, it will apply a confidence, or result score, to each entity and return the best result. For example, if you search for “Stephen King” it’s a safe bet that you will get the famous horror author and not the US politician, Steve King.
Some examples are a bit less clear cut though. In some cases, according to Google’s knowledge graph API, the book “The Shining” isn’t even in the top 10 relevant entities for that search term.
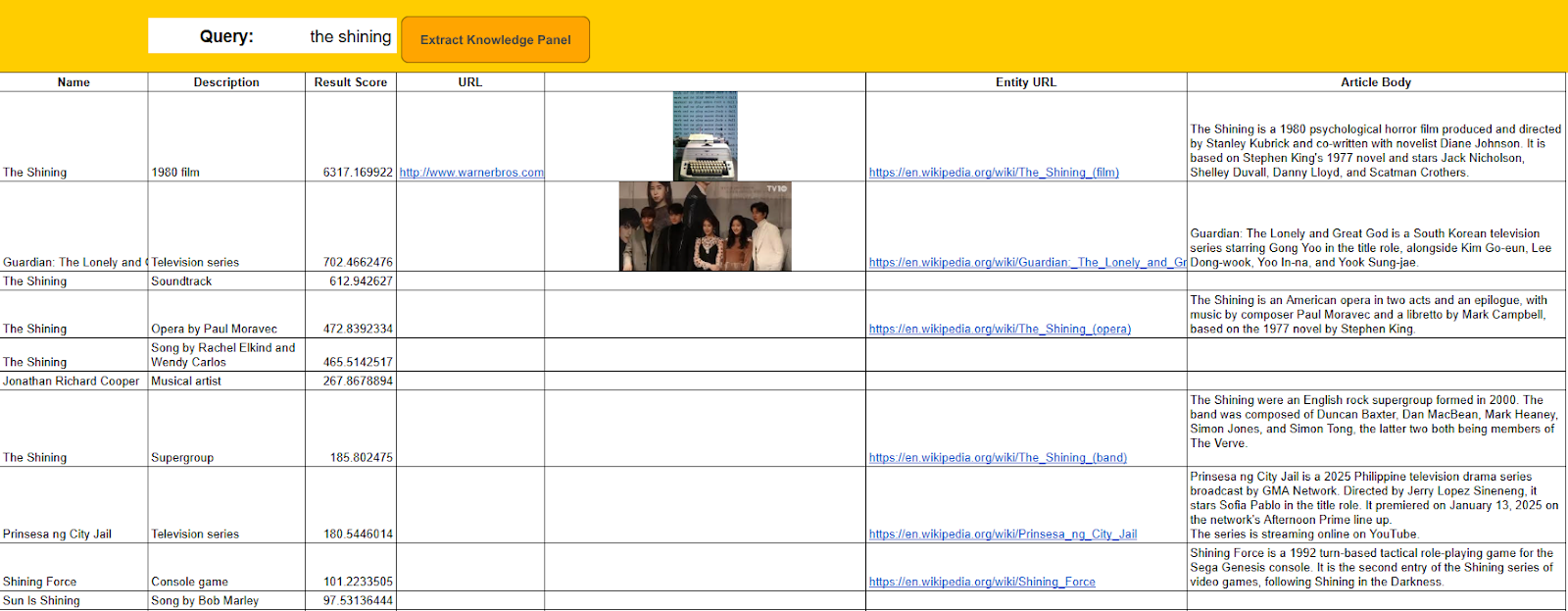
So when you’re writing about a particular topic, ensure that there is no grey area on what you’re writing about, or Google may assume that you’re writing about a completely different entity. For a better understanding of knowledge graph results, you can use this Google Sheets template.
The importance of associations
Entities do not exist in isolation - they are almost always connected with other entities.
To better understand the concept of entity relationships, let’s look at the concept of semantic triples. This is how the relationship between two entities is defined. For example, we know that:
-
The Shining,
-
Was written by
-
Stephen King
We also know that:
-
Jack Torrance
-
is a Character from,
-
The Shining
These triples make up the core of the knowledge graph and enable machines to understand how different entities are related to each other. For example, from the two pieces of information above we can deduce that Jack Torrance is a character who was written by Stephen King based on the relationships described in those triples
So let’s step it up a notch. Consider the following relationships:
| Subject | Predicate | Object |
|---|---|---|
| Stephen King | wrote | The Shining |
| The Shining | features | Torrance Family |
| Torrance Family | includes | Jack Torrance |
| Torrance Family | includes | Wendy Torrance |
| Torrance Family | includes | Danny Torrance |
| The Shining | set in | Overlook Hotel |
| Overlook Hotel | located near | Boulder, Colorado |
| Stephen King | wrote | Rita Hayworth and Shawshank Redemption |
| Rita Hayworth and Shawshank Redemption | features | Andy Dufresne |
| Rita Hayworth and Shawshank Redemption | features | Shawshank Prison |
I can represent this information as a simple diagram below:
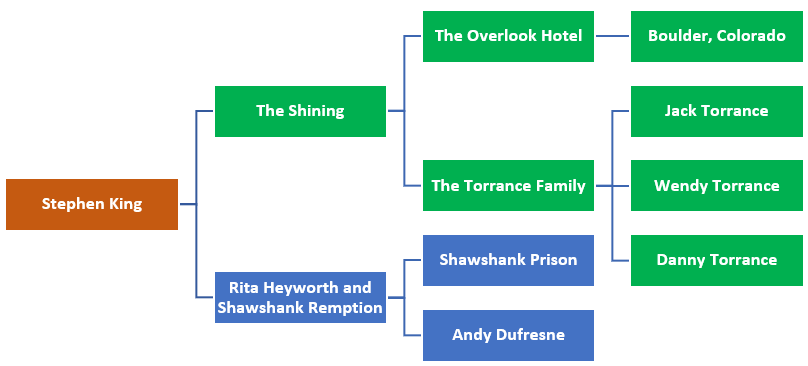
From this, we can determine the following information; Jack Torrance stayed at the Overlook Hotel. The Shining is based near the town of Boulder Colorado, Jack Torrance and Andy Dufresne are both characters written by Stephen King, etc.
This is a simple representation using only a few entities and relationships, but there’s nothing stopping us from adding more and more to it. For example, we could take it a step further by adding the Stanley Kubrick movie along with the actors; Jack Nicholson and Shelley Duvall. But I don’t have time for that. The internet is full of these associations and the more entities we add to the knowledge graph, the better it can determine how they relate to each other.
Let's look at a practical example; if you Google "who played jack torrance in the shining?", Google will interpret that using natural language algorithms as follows:
Actor > [who played the character] > Jack Torrance > [who is a character in] > The Shining (film)
This makes it really easy for Google to know the answer of Jack Nicholson, which is demonstrated in the screenshot below:

Sentiment matters
When I search for “best stephen king book”, the autocomplete recommends “It”. Personally, clowns creep me right out so I’ll give that one a miss. However, Google is able to instantly give me that suggestion based on it’s knowledge graph.
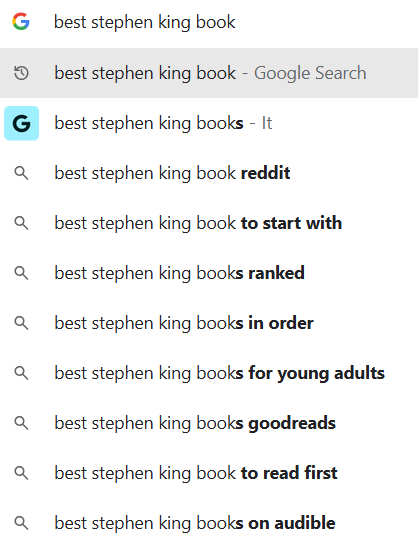
This is achieved through 2 methods; aggregating reviews and analysing sentiment. So when a website reviews a product, or in this case a book, Google can understand what the review score is. When it collates the reviews for each book from across the web, its not that hard for it to determine which is considered to be the best.
Analysing sentiment is a bit more complex. When Googlebot encounters an entity on a web page, it is able to apply a sentiment score based on the text around it. So, for example, if a Reddit forum was asking for the best Stephen King book and someone replied with “It” or “The Stand”, that would come with a high sentiment score. However, if someone was reviewing the latest book and used the phrase, “this is one of his worst books, it feels like he’s running out of ideas”, then that would have a low sentiment score.
Sentiment is important because Google wants to be confident that it is returning the best brands for your query. Years ago, “stinkbait” was a legitimate link building strategy. The concept is simple, state something extremely controversial to get people talking about your brand and they will link to you in the process. When done well, it can create an insane number of backlinks. However, if Google knows that all of those links come with a negative context, would it still want to reward your site?
So what does this have to do with SEO?
I’m glad you asked. Google’s knowledge graph has 2 main benefits; it can categorise your website and the products you sell far more efficiently but it can also use the information it has about you to understand your brand from an EEAT (experience, expertise, authority and trust for those of you who don’t know) point of view. So let’s look at some of these principles below.
Build a brand
So instead of an author, let’s imagine we’re talking about Martin Lewis, founder of moneysavingexpert.com. Whilst Stephen King is synonymous with horror fiction, Martin Lewis is a household name in the UK when it comes to personal finance. He has founded several businesses in this field, written books, provided interviews and has had many TV appearances. As far as Google’s knowledge graph is concerned, he is an expert.
So fill out those online profiles, build citations, utilise 3rd party reviews and build your digital PR. Get people talking about your brand in a positive way to build that brand sentiment. Use the experts representing your brand so that everyone knows that your brand is an authority in your niche.
Understand Schema
There is a lot of debate and misunderstanding about the role and benefit of schema for your website. To put it simply, schema can define the entities that are on your web page as well as clarify what the intent of the page is.
One of the most powerful applications of schema is the use of the sameAs field. Say if you’re a well known and respected authority in your field, you can use sameAs to reference other places where you have an online presence so search engines know that your are the same person. You can apply this to other entities on your page as well by referencing the relevant Wikipedia. Check out the entity analyser from Inlinks for an example.
Keep it consistent
If you’ve ever done local SEO you’ve probably heard about NAP (name, address, phone number) and been told to keep it consistent across your local citations. The reason behind it is very simple; you want Google to know that the citation is about you.
The same is true for any online citations. For example, if the URL on your social profile is wrong (or even missing!) then could Google think that this is a different company with the same name?
The same could be said about a product that you sell. If you get the name of the product slightly wrong or if the brand is spelt incorrectly, will Google make the link between this and the other websites selling the same thing? Will they get prioritised over you as a result?
Cluster it
Ensure that your website architecture and internal linking structure are rock solid. In the same way that Google can understand the relationship between entities, it can also understand the relationship between the pages on your website. This is known as your link graph. Linking between topically related content makes it easier for search engines to understand your website and how they are relevant to the entities within it.
Stay on topic
Imagine if Stephen King wrote a romantic novel. No ghosts, no monsters and no general creepiness. Just a good old fashioned boy meets girl romance novel. Would it be expected? Would we trust it?
Similarly, if you ran a website selling conference chairs and suddenly started talking about gardening supplies it would be confusing to say the least. How would Google interpret that brand as part of their knowledge graph?
So make sure your content is relevant to your brand, is helpful for your customers and makes sense for search engines.
Write for h̶u̶m̶a̶n̶s̶,̶ ̶n̶o̶t̶ machines
You often hear people who work in SEO, and especially those who work at Google, talk about writing for humans, not machines. Whilst this is true, you also need to bear in mind that machines are still going to be reading your content and you need to give them an extra helping hand. I won’t bore you with concepts like tokenisation or anything like that, but writing for robots should be done in two ways; structure and semantic cues.
Structure your page in a logical way that allows users to know exactly what to expect with each subheading. If any segments do not aid users, get rid of them as they’re unlikely to help robots understand your page either.
Keeping your content concise and cutting the fluff (writing to word count can f*** off) will make it easier for bots to understand the content. You can also add cues like “in summary”, “a common mistake” or step numbers (thanks SEJ for that little nugget) know the context and sentiment of your content segments.
You also need to be specific with your claims. For example, when writing a case study instead of saying “+75% sales” could say “we improved sales from X to Y with an increase of 75%”. This cuts out the ambiguity so the bots know exactly what your stating on your page as well as being able to interpret the sentiment more accurately.
In the age of AI, an understanding of how knowledge graphs and entities work will become more important as these form the foundations of how LLMs work. As SEOs scramble to optimise brands for AI search, understanding how they are linked to the entities which inform them will give you the edge.